Final Write Up
Project Summary
Initially, we planned to implement parallel versions of two lossless data compression algorithm, Lempel-Ziv-Storer-Szymanski (LZSS) compression and Huffman coding, on many-core CPU. However, after we implemented a naive parallel version of both algorithms, we found that the problems we need to consider for both algorithms are very similar. Then, we decided to focus on parallelizing Huffman Coding since it has more parallelizable components and has a higher potential parallel performance gain. We will make use of SIMD intrinsics, ISPC compiler and OpenMP library to perform parallel compression. We will also conduct detailed analysis for our implementation considering characteristics including memory bandwidth, CPU usage and cache behavior, and compare the performance with the sequential implementation.
Background
As internet are getting popular in 1980s, many compression algorithms are invented to overcome the limitation of network and storage bandwidth. There are mainly two types of compression algorithms. Lossy compression algorithms are mainly used to compress image and audio. Lossless compression algorithms are more useful in many other situations like compression in storage device where loss of data is unacceptable. Our project is focusing on parallelizing one of the most popular compression algorithm called Huffman Coding. Huffman Coding is the process of finding the optimal prefix code for a set of source symbols. After the prefix code table is built, more common source symbols will be encoded using less bits. Huffman coding can also be combined with other compression algorithm like LZSS to provide even higher compression ratio. Currently, Huffman Coding is implemented sequentially in many compression libraries. Thus, parallelizing Huffman Coding becomes very important to improve the performance of those compression libraries.
Approach
Huffman Coding Overview
Huffman Coding Compression has four main steps:
- Reading from a input file and build a histogram to count the frequency of each byte.
- Building a Huffman Tree from the histogram.
- Traversing the Huffman Tree and build the prefix code table.
- Encoding the input file using the prefix code table.
Initially, we use libhuffman as our starter sequential codes. libhuffman is a single-threaded pure C library and command line interface for Huffman Coding, released under a BSD license. We found it from github and sourceforge. We modified it to be using C++11 and change many inefficient components in it to make it as optimized as possible. We also read the entire files into memory before the compression and decompression starts to avoid being bottlenecked by disk bandwidth. Then, we use it as the baseline for our evaluation. After we running the sequential Huffman Coding on a 5.5 GB Wiki Dataset, we get the following graph.
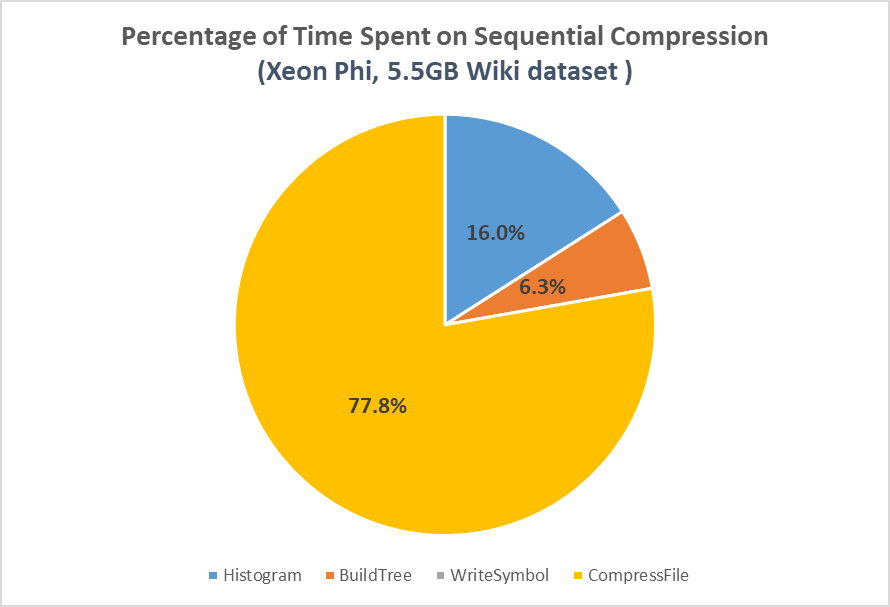
Figure 1. Compression Time Component
Parallelize Compression
As we can see from the graph, 77.8% of the time is spent on encoding the input files. Thus, parallelizing encoding step becomes our first step. We are mainly using OpenMP to utilize the multi-core CPU and in the meantime to provide a clean interface without dealing with C++ Thread Library. Also, to avoid communication between threads, we divide the input file to equal size chunks and each thread will be working on their own chunk. When writing to the compressed file, we will precompute the size of compressed chunk each thread will produce. Then, use prefix sum to get the output offset so that each thread will know where they should write to. Those offset information will also be written to the front of compressed file as the metadata. The final compressed file will look like the following

Figure 2. Compressed File Format
We conduct the analysis on the total compression time to identify the bottleneck as our development goes on. Figure 3 shows the percentage of time spent on each step of the compression when we only parallelize the second pass of the data to do real compression. Compression data (yellow region) takes almost 80% of the time in the sequential version. However, when we parallelize it and increase the number of threads, the compression data time drops dramatically and now histogram generation (blue region) becomes the bottleneck. It matches with the Amdahl’s Law. Note that in our approach, the building tree step (orange region) requires us to pre-compute the compressed output size and we also parallelize the pre-computation in our first implementation so that we can see the building tree time also drops when the number of threads increases.
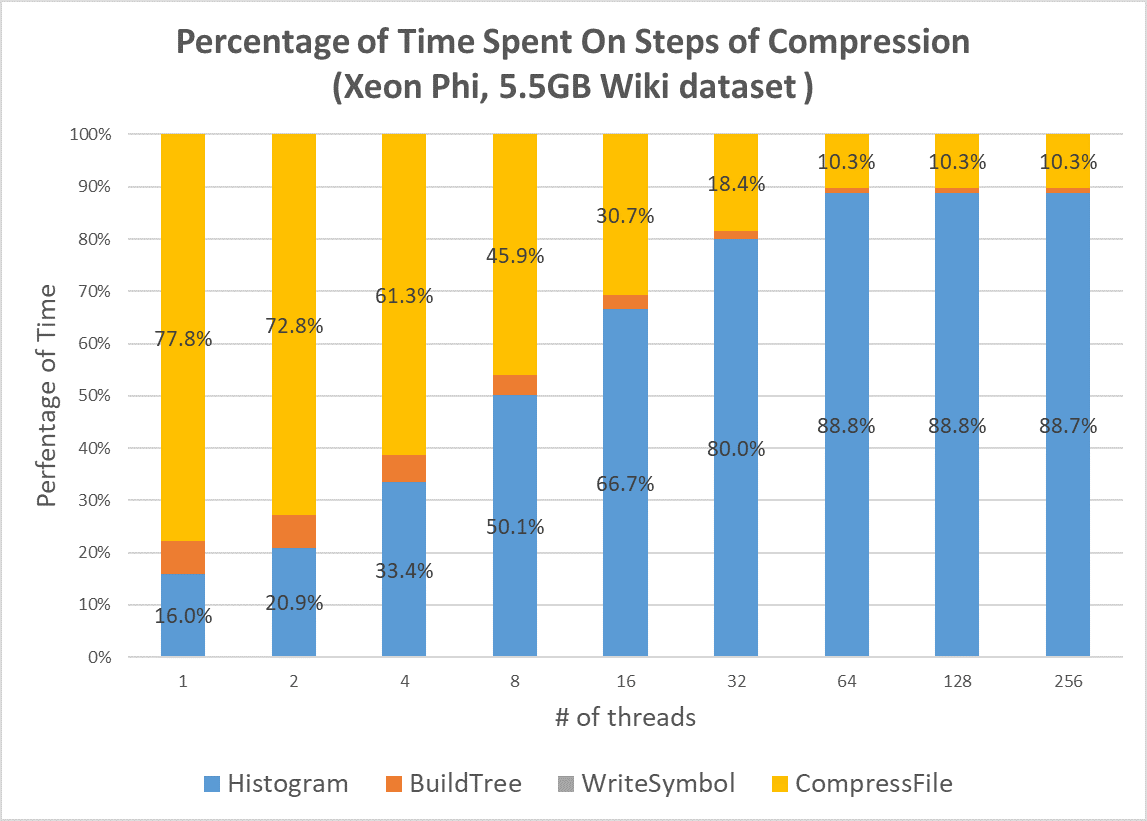
Figure 3. Percentage of Time Spent On Steps of Compression (Parallel Encoding Only)
We then tackle with the new bottleneck by parallelizing the histogram construction. To avoid communication between different threads, each thread will be assigned a chunk of input file. Then, each thread will run through their chunk of input file and count the frequency into a local histogram. After this step is done, we will add a barrier to synchronize all threads. Then, each thread will be responsible for merging part of global histogram. By using this two parallel steps, we achieve linear speedup for histogram generation. Figure 4 shows the time analysis with parallel encoding and parallel histogram generation. After we parallelize both steps, the compression distributions are quite similar as the number of threads increases. It shows that parallelizing both histogram construction and data encoding is the correct way to go.
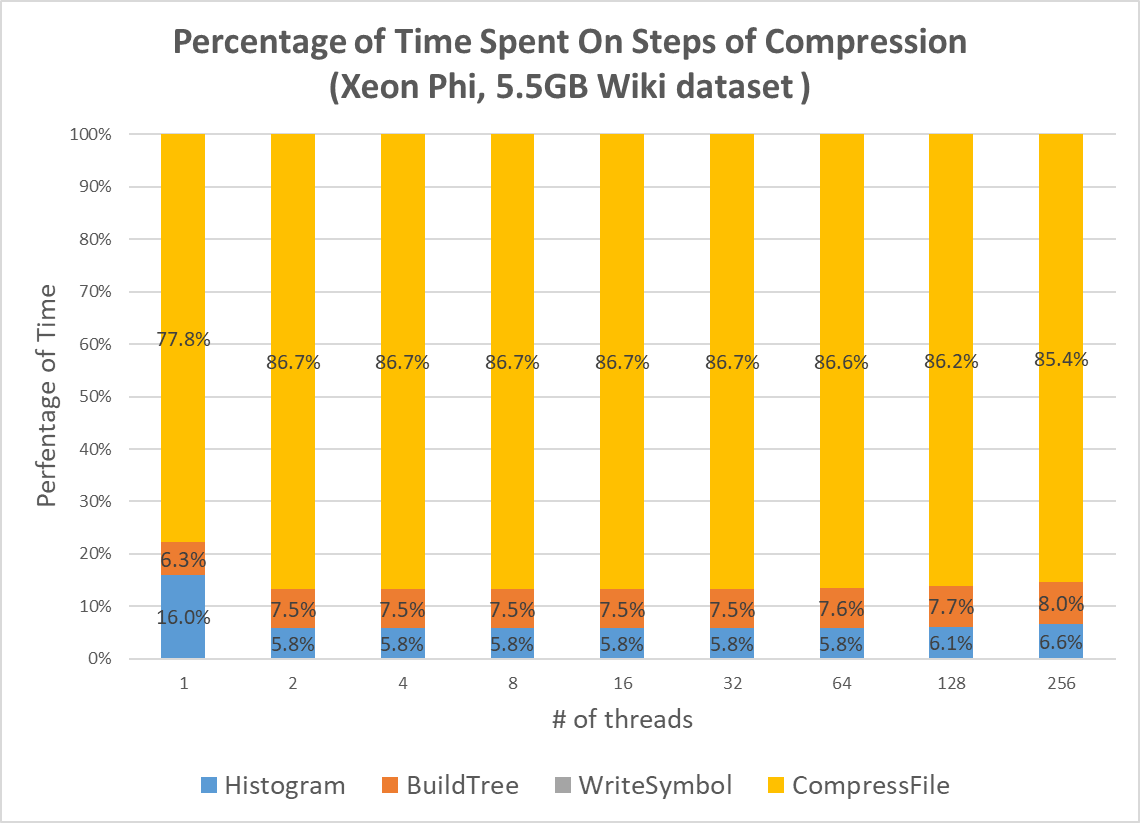
Figure 4. Percentage of Time Spent On Steps of Compression (Parallel Encoding + Parallel Histogram)
Parallelize Decompression
As for the decompression. The first step is to read metadata from the file and build the Huffman Tree in memory. Then, start decoding the file by traversing the Huffman Tree based on compressed bits. After we run the sequential version, we found about 99% of time is spent on the second step. Thus, we focused on parallelizing the second step. Corresponding to the parallel encoding step, the parallel decoding will start by reading the chunk offset from the header. Then, each thread will start reading from input file at that offset. In this way, there is no communicating between threads, we are able to achieve linear speedup for decompression.
Why not ISPC and SIMD instructions
During the development, we also tried to use ISPC to utilize SIMD unit. But there exists several issues showing that huffman coding compression and decompression may not be a perfect workload for SIMD. Our thought is to use SIMD to read in an array of input bytes and calculate how many compressed bits each byte has. Then, do a prefix sum to calculate the offset. Then, use SIMD to pack compressed bits together to avoid inefficient gather and scatter operations. However, this does not work well. Since this whole process for four elements will requires more than 4x instructions than the sequential code. Thus, using SIMD may probably be slower than sequential code in this case. Also, between SIMD iteration, we need to remember how many bits are written in the previous iteration and deal with bit-level conflicts. There is no easy way to express that dependency in ISPC. Also, directly dealing with bits instead of bytes using SIMD is very hard. Thus, we decided to focus on utilizing multi-core instead of SIMD units.
Results
We conduct evaluation on parallel huffman coding compression and decompression on three platforms: GHC Machine, Xeon Phi Co-processor, many-cores NUMA CPU.
GHC Machine (Xeon E5-1660 v4 @ 3.20GHz, 8 Cores, 16 Threads)
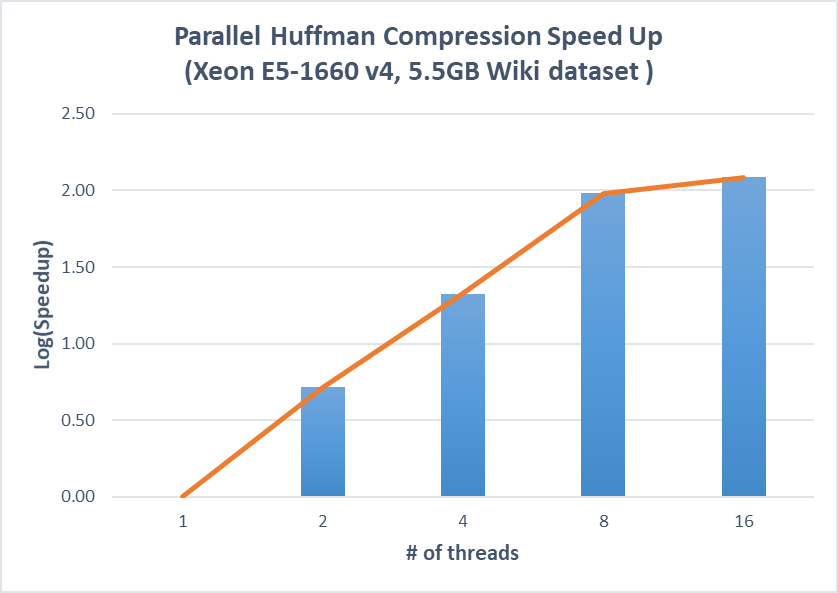
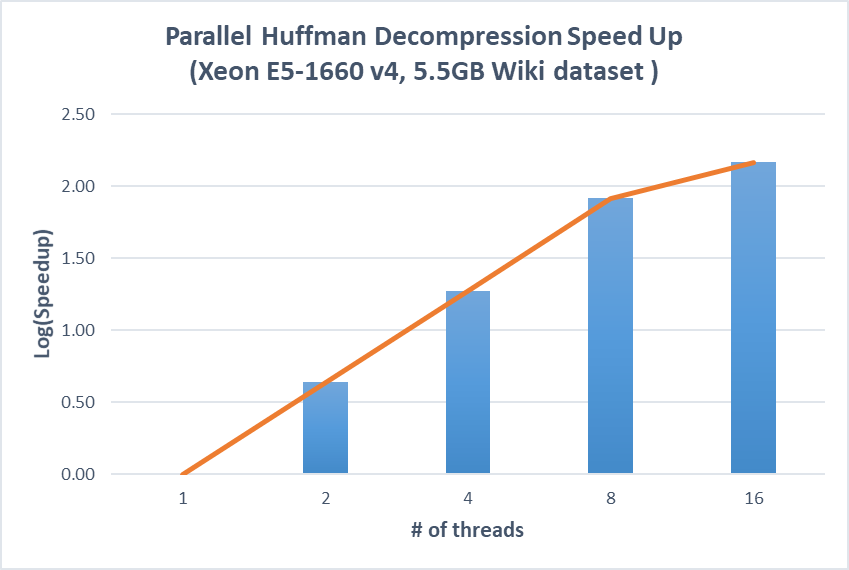
Figure 5. Speedup on parallel huffman compression and decompression versus the optimized sequential implementation (Xeon E5-1660)
We first runs Huffman compression and decompression using 500MB Wiki dataset on the GHC machines, which has 8 cores and 16 hardware threads. The result shows a linear speedup until 8 threads are used while there is little speedup from using 8 threads to 16 threads. This makes sense because there are only 8 physical cores in the machine and hyperthreading helps little when huffman compression and decompression are CPU bound.
Xeon Phi (KNL) Co-processor (68 Cores, 256 Threads)
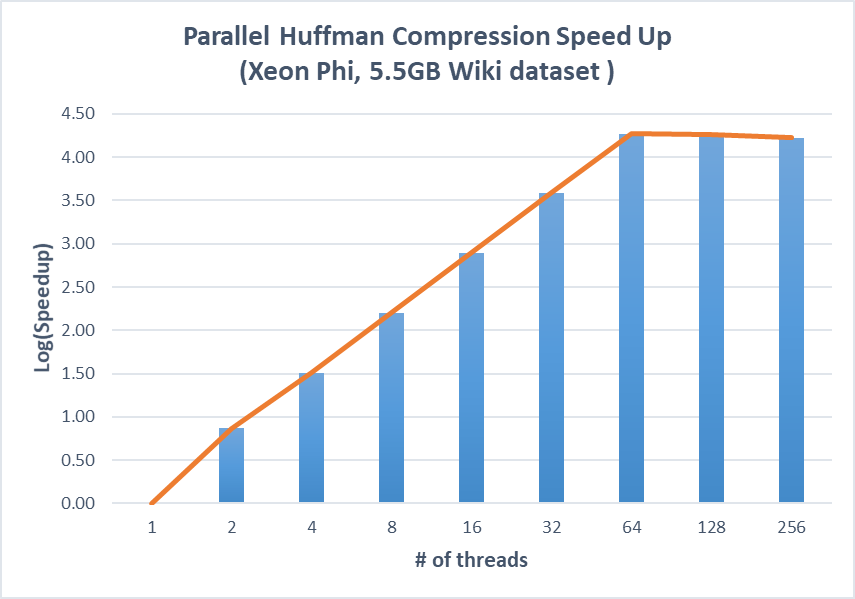
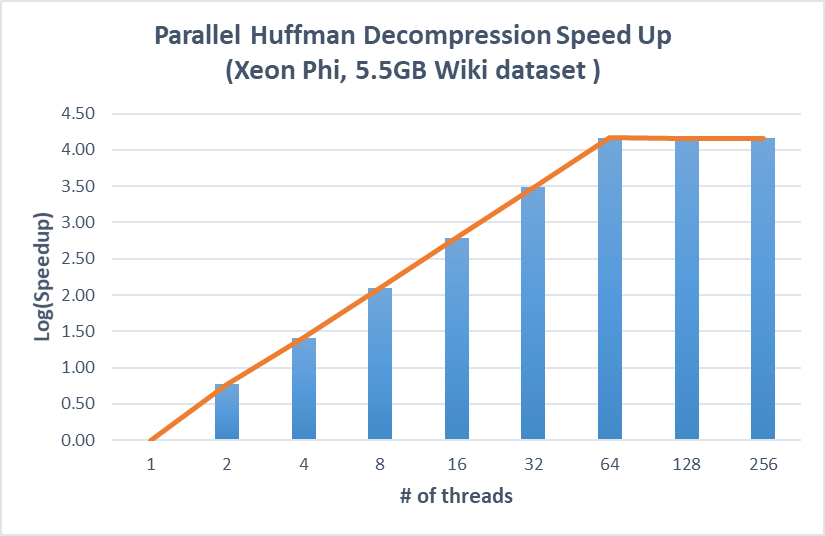
Figure 6. Speedup on parallel huffman compression and decompression versus the optimized sequential implementation (Xeon Phi)
We then runs Huffman compression and decompression using 5.5GB Wiki dataset on Xeon Phi, which has 68 cores and 256 threads. The results are similar and our approaches can achieve linear speedup until we fully utilize all the physical cores and benefit little from hyperthreading.
NUMA CPU (Xeon E5-2699 v4 @2.20GHz, 88 Cores, 4 Sockets, 88 Threads)
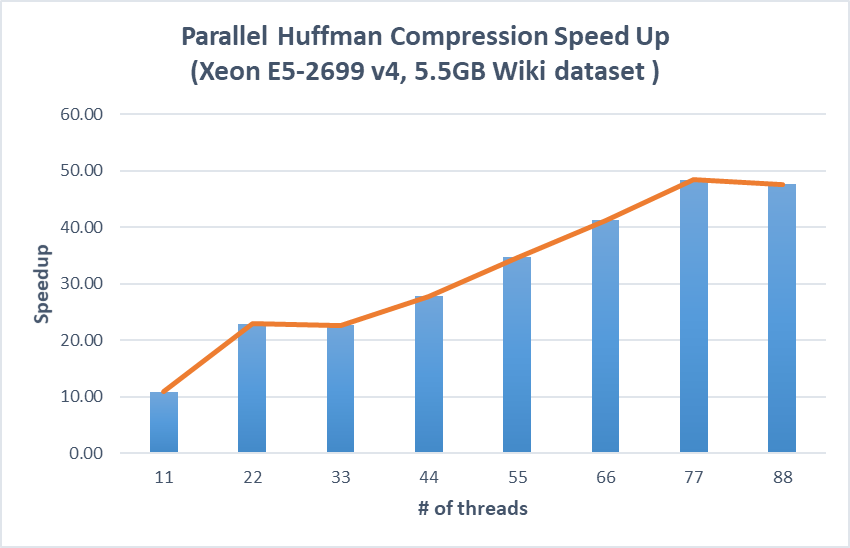
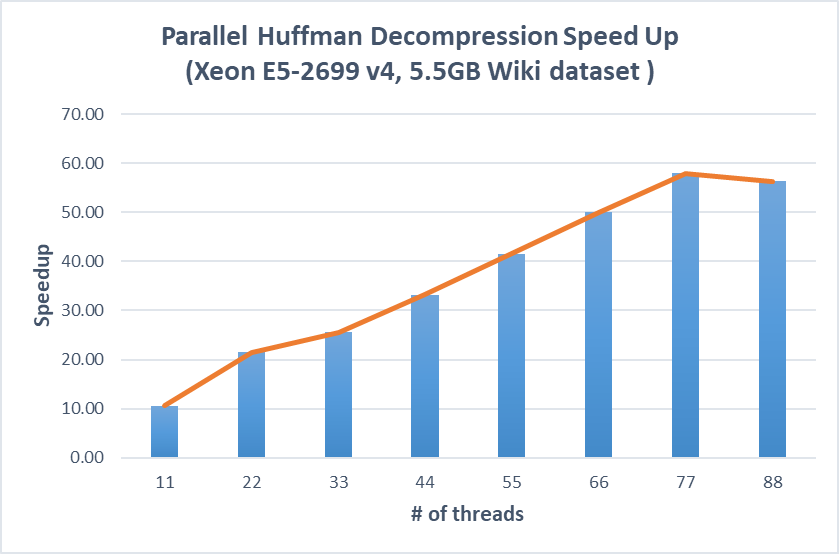
Figure 7. Speedup on parallel huffman compression and decompression versus the optimized sequential implementation (Xeon E5-2699)
We also try to run our algorithm on a NUMA CPU, which has 88 cores and 4 sockets with each of the 22 cores placing in the same socket. We configure the CPU affinity policy of OpenMP such that threads are bound to cores according their thread ids. Here we are using the absolute value of the speedup instead of the log speedup because we want to see the behavior of placing threads across sockets. The result shows that when the threads are running in the same socket, the speedup trend is not affected. But when the threads are running across different sockets, we see almost no speedup (22 to 33 threads) or even slow down (77 to 88 threads). This is caused by interconnect traffics across sockets because we use the first thread to load the file into memory and this memory are allocated on the first socket only with the default first touch policy. We then further parallelize the file loading step to try to make memory allocated across sockets to reduce the interconnect traffics but we see little improvement. We think that in order to tackle with this problem, we may need to use NUMA-aware memory allocation system calls or enforce other NUM-aware memory allocation policies but since they are platform specific and the NUMA libraries are absent in the intel cluster, we find it hard to do further improvement on this issue.
References
- Patel, R. A., Zhang, Y., Mak, J., Davidson, A., & Owens, J. D. (2012). Parallel lossless data compression on the GPU (pp. 1-9). IEEE.
- Ozsoy, A., Swany, M., & Chauhan, A. (2012, December). Pipelined parallel lzss for streaming data compression on gpgpus. In Parallel and Distributed Systems (ICPADS), 2012 IEEE 18th International Conference on (pp. 37-44). IEEE.
- Ozsoy, A., Swany, M., & Chauhan, A. (2014). Optimizing LZSS compression on GPGPUs. Future Generation Computer Systems, 30, 170-178.
- Michael Dipperstein, LZSS(LZ77) Discussion and Implementation, http://michael.dipperstein.com/lzss/
Work Division
- Chen Luo: LZSS sequential version, LZSS Naive Parallel, Huffman Coding OpenMP
- Zhanxiang Huang: Huffman Coding sequential version. Huffman Coding OpenMP, Huffman Coding ISPC
Project Middle Checkpoint (Apr 25th)
Project Status Summary
Since the beginning of the project, here are some of the progress we made.
Huffman Compression
- Finish researching and reading literatures on the implementation and current optimizations on the Huffman compression algorithms. The workflow of Huffman encoding mainly contains two pass of the input data and four stages: Generate frequency histogram for all the input bytes (1st pass), Build huffman tree based on the histogram, Construct huffman code for all the bytes in the histogram bin, Encode the original data into huffman code (2st pass). We used libhuffman, an open source sequential version of the huffman algorithm as the reference implementation and benchmark [2].
- Finish the naive implementation of huffman encoding. Specifically, we refactor the libhuffman code to fix some performance bug, remove the useless codes and make it object oriented. We also add timer to measure the percentage of time spent in different stage of huffman encoding using Wikipedia dataset. The results show that a majority of time is spent on the second pass of the data to convert original bytes into huffman codes and generating frequency histogram.
- Next Step. We are implementing the parallel huffman encoding algorithm focusing on the bottleneck of encoding data in the second pass and generating histogram in the first pass. We are trying different approaches. For example, dividing the data into blocks and creating threads to do the whole huffman encoding workflow independently, which may achieve good speed-up but may decrease the compression ratio. We are also trying to use data parallelism only for histogram generation and data encoding so different blocks of the data are using the same huffman tree to construct huffman code, which will not hurt the compression ratio. We will also try to parallelize the huffman decoding algorithm which need to reconstruct the huffman code mapping and decompress the encoded data.
LZSS Compression
- Understand the details of LZSS algorithm. We have looked at some literatures and understood some of the optimizations that can be done for LZSS algorithm such as packing the encoded bits into a single byte. We also found out the trade off between different string comparison algorithms. Specifically, the easiest algorithm is linear search, where we compare second string with each substr within first string sequentially. There are also other algorithms such as using linked list or hash table to speed up this process.
- Finished the sequential version of the algorithm. We found an sequential implementation of LZSS online [1] and did some modifications to it. Specifically, we add timer to identify the bottleneck, fixed some existing bugs, and make it more object oriented. In the sequential version, there are three main steps. First step is to read bytes from file and put them in a lookahead buffer. Secondly, compare bytes in lookahead buffer with bytes in the sliding window and find the longest match. Thirdly, write the encoded offset + length to the output file and shift the sliding window to include matched characters. In theory, the first step and third step are mainly doing sequential file I/O, most of the time will be spent on the second step, which is doing string match. However, we found that most of the time is spent in the first step. It turns out that it’s a problem in the implementation where the program only read one byte from file at a time.
Deliverables on the Competition
- Percentage of time spent on each stage of the compression and decompression algorightms.
- Speed-up graph on parallel Huffman and LZSS compression vs. the sequential implementation with different number of cores using different datasets.
- Speed-up graph on parallel Huffman and LZSS decompression vs. the sequential implementation with different number of cores using different datasets.
Issues & Concerns
Huffman Compression
All huffman algorithms are using a byte (8-bit) as the basic unit of the histogram, in other words, the maximum number of different leaves in the huffman tree is 256. We will try to use different number of bit (i.e. 16-bit, 32-bit) as the compression unit. Huffman compression works well when the distribution of the compression is highly skew. There is a trade-off on how many bits are used as the compressed unit because the more bits we use, the more space we can reduce for the less frequent code, but the less opportunity we can have for the skew distribution and the more time is spent on constructing the huffman tree and the huffman code.
LZSS Compression
The only issue now is to rewrite the file I/O part of the sequential algorithm so that it can read a block size of data at a time instead of one byte of time. After we fix this issue, we will start parallelizing the linear search string match and string matching using hash table. Then compared to the sequential code to see how much speedup we get.
Reference
[1] LZSS algorithm details. http://michael.dipperstein.com/bitlibs/index.html
[2] Libhuffman: https://github.com/drichardson/huffman
Project Proposal
Summary
We are going to implement parallel versions of two lossless data compression algorithm, Lempel-Ziv-Storer-Szymanski (LZSS) compression and Huffman coding, on many-core CPU. We will make use of SIMD intrinsics, ISPC compiler and OpenMP library to perform parallel compression. We will also conduct detailed analysis for our implementation considering characteristics including memory bandwidth, CPU usage and cache behavior, and compare the performance with the sequential implementation.
Background
As internet are getting popular in 1980s, many compression algorithms are invented to overcome the limitation of network and storage bandwidth. Lossy compression algorithms are mainly used to compress image and audio. However, lossless compression algorithms are more useful in many other situations like compression in storage device where loss of data is unacceptable. The most famous lossless compression algorithm LZ77 was invented by Abraham Lempel and Jacob Ziv in 1977. After that, there are many algorithms derived from LZ77. One of them is LZSS, which is used in RAR. Another very popular compression algorithm is called Huffman coding, which generate prefix coding for encoding targets. These two algorithms plays an important role in many compression libraries and they are currently implemented sequentially in those libraries.
The Challenge
- In LZSS algorithm, the compressor will keep track of a sliding window as the encoding context. For the following sequence of characters, the compressor will try to find if there is any repeated sequence in the sliding window. If found, replace the following sequence with (offset, length) pair. Since this sliding windows are always moving sequentially, there isn’t a clear way to parallelize it. We may need to modify the algorithm to make it more easily to parallelize.
- In Huffman coding, there are three main steps. First, calculate the frequency of all characters. Then build a min heap using frequency as the key and characters as the value. Finally, in each iteration, the first two element in min heap will be popped out and inserted into the Huffman tree. Since the whole process is using a shared min heap and a shared tree, it’s unclear how to parallelize it efficiently. The synchronization overhead may cause the bad parallel implementation to achieve very poor scalability.
Goals and Deliverables
75% goal
- Finish a correct implementation for both sequential and parallel versions of lossless compression algorithms LZSS and Huffman Coding.
- Run the algorithms on top of regular multi-core machines and Xeon Phi Coprocessor.
100% goal
- Evaluate the memory bandwidth, memory footprint, CPU efficiency of parallel LZSS and Huffman Coding to identify bottlenecks.
- Perform optimization for parallel LZSS and Huffman Coding based on the evaluation results. Improve the compression speed without consuming more system resources and sacrificing compression ratio.
- Conduct detailed analysis on our parallel implementation running on Xeon Phi Coprocessor. Compare the performance of the parallel and sequential version as well as the behavior running on different platform (Xeon Phi Coprocessor, regular multi-core machine, single core machine) by providing speedup graphs.
125% goal
- Achieve comparable or even beat state of the art LZSS and Huffman Coding implementation.
- Modify the implementation to adapt CUDA. Run our algorithm on top of GPU.
Resources and Platform Choice
- Language/Compiler/Library: C/C++, ISPC, SIMD intrinsics, OpenMP
- Platform:
- Intel Xeon Phi coprocessor that supports 512bit AVX instructions
- General multi-core processor (i.e. GHC machines)
- References
- Patel, R. A., Zhang, Y., Mak, J., Davidson, A., & Owens, J. D. (2012). Parallel lossless data compression on the GPU (pp. 1-9). IEEE.
- Ozsoy, A., Swany, M., & Chauhan, A. (2012, December). Pipelined parallel lzss for streaming data compression on gpgpus. In Parallel and Distributed Systems (ICPADS), 2012 IEEE 18th International Conference on (pp. 37-44). IEEE.
- Ozsoy, A., Swany, M., & Chauhan, A. (2014). Optimizing LZSS compression on GPGPUs. Future Generation Computer Systems, 30, 170-178.
Schedule
- 4/10 - 4/14: Read papers and understand the basic algorithm. Setup development environment.
- 4/15 - 4/21: Implement the naive but correct parallel version of the two algorithms (75% goal).
- 4/22 - 4/25: Benchmark the naive implementation, identify the bottlenecks.
- 4/26 - 5/4: Optimize the algorithms to tackle with the bottlenecks and improve compression speed. (100% goal)
- 5/5 - 5/11: Conduct experiments to analysis the optimized versions, compare with the sequential implementation, explain the trade-offs and finish write-up.